Автоматический перевод
Эта статья была автоматически переведена с оригинальной английской версии.
Руководство по развертыванию LoRAX: тысячи LoRA-адаптеров в Kubernetes
Раньше обслуживание десятков дообученных больших языковых моделей обычно означало один GPU на модель. LoRAX (LoRA eXchange) держит одну базовую модель в памяти и на лету подменяет легковесные LoRA-адаптеры для каждого запроса. Стоимость токена остается примерно постоянной даже при росте числа fine-tune-моделей.
В этом руководстве разбирается, что такое LoRA, когда стоит выбрать LoRAX вместо vLLM, как развернуть его в Kubernetes с официальным Helm chart и как вызывать REST, Python и OpenAI-совместимые API.
Контекст: что такое LoRA?
Low-Rank Adaptation (LoRA) замораживает веса предобученной модели и внедряет небольшие матрицы rank-decomposition в каждый слой Transformer. Вместо переобучения всей модели вы обучаете небольшой набор "diffs", которые фиксируют новое поведение.
Полный fine-tune модели на 7B — это файл размером 20GB+. LoRA-адаптер для той же модели — около 100MB. Именно эта разница делает возможным динамический serving: вы можете хранить тысячи адаптеров на диске и загружать нужный в память GPU за миллисекунды.
Какую проблему решает LoRAX
Традиционный multi-model serving дорог. Каждой дообученной модели нужна своя память GPU, поэтому для обслуживания 50 моделей под конкретных клиентов нужны 50 deployment'ов или как минимум память в 50× больше. Стоимость линейно растет с каждой новой вариацией.
LoRAX — это проект Apache 2.0 от Predibase. Он расширяет Hugging Face Text Generation Inference server за счет динамической загрузки адаптеров, многоуровневого кэширования весов и multi-adapter batching. В совокупности это позволяет обслуживать сотни tenant-specific LoRA-адаптеров на одном GPU класса Ampere без потери throughput и latency.
Ключевая идея: LoRA fine-tuning создает небольшие delta-веса, а не полные копии модели. LoRAX держит на GPU только базовую модель и по запросу подмешивает веса адаптера. Адаптеры, которые не используются, не занимают VRAM.
Как это работает
Динамическая загрузка адаптеров
Веса адаптера подмешиваются just-in-time для каждого запроса. Базовая модель остается в памяти GPU, а адаптеры загружаются на лету, не блокируя остальные запросы. Вы можете держать каталог из тысяч адаптеров, но платить памятью только за те, которые реально обрабатывают трафик.
Многоуровневое кэширование весов
LoRAX распределяет адаптеры по трем уровням: VRAM GPU для горячих адаптеров, RAM CPU для теплых и диск для холодного хранения. Эта иерархия помогает избежать out-of-memory сбоев и держит время переключения достаточно низким, чтобы пользователи этого не замечали.
Непрерывный multi-adapter batching
Именно здесь LoRAX меняет поведение batching. Он расширяет continuous batching так, чтобы параллельно работать с разными адаптерами, поэтому запросы к разным fine-tune-моделям могут делить один и тот же forward pass. Бенчмарки Predibase показывают, что обработка 1M токенов, распределенных по 32 разным адаптерам, занимает примерно столько же времени, сколько 1M токенов на одной модели.
TGI под капотом
LoRAX построен поверх Hugging Face Text Generation Inference (TGI), поэтому вы получаете оптимизации TGI: FlashAttention 2, paged attention, SGMV kernels для multi-adapter inference и streaming responses. Это TGI плюс динамическое переключение адаптеров.
Стоимость токена остается примерно постоянной
График показывает это наглядно. Выделенные deployment'ы (темно-серый) масштабируются линейно: вдвое больше моделей — вдвое выше стоимость. LoRAX (оранжевый) удерживает стоимость токена почти постоянной по мере добавления адаптеров. Даже hosted API fine-tune от провайдеров вроде OpenAI (светло-серый) не могут конкурировать с этим в multi-model workload.
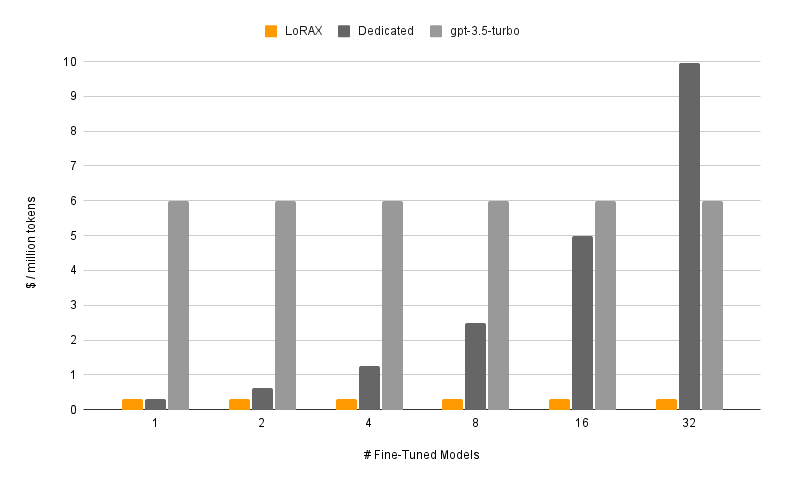
Стоимость миллиона токенов при обслуживании растущего числа дообученных моделей. LoRAX остается почти на одном уровне благодаря multi-adapter batching; выделенные deployment'ы масштабируются линейно. Источник: LoRAX GitHub.
Поток обработки запроса

Когда использовать LoRAX
LoRAX имеет смысл в нескольких конкретных сценариях.
- Multi-tenant SaaS. Вы строите платформу, где каждый из 500 клиентов получает chatbot, дообученный на его данных. Традиционный подход потребует 500 model deployment'ов. LoRAX обслуживает все 500 с одного GPU, загружая нужный адаптер при поступлении клиентского запроса.
- Маршрутизация по доменным экспертам. Вы поддерживаете специализированные LLM для права, медицины, финансов и инженерии. Вместо четырех отдельных deployment'ов 13B LoRAX запускает одну базовую LLaMA 2 13B и направляет запрос к нужному адаптеру в зависимости от домена.
- Быстрые эксперименты. Тестируете 10 подходов к fine-tuning в production? Разверните LoRAX один раз и переключайтесь между вариантами, меняя параметр
adapter_id. Без изменений инфраструктуры и перезапуска сервиса. - Развертывания с ограниченными ресурсами или на edge. Один NVIDIA A10G может разместить квантованную базовую модель 7B плюс десятки task-specific адаптеров вместо одного GPU на модель.
Архитектура: иерархия памяти и планирование запросов
LoRAX построен вокруг трехуровневой иерархии памяти. Понимание этого помогает прогнозировать производительность и планировать емкость.

LoRAX рассматривает каждый адаптер как легковесное "представление" общей базовой модели. Планировщик коалесцирует запросы так, что обслуживание 32 разных адаптеров может быть таким же быстрым, как обслуживание одного, даже при throughput в миллион токенов. Вес адаптеров обычно составляет 10–200MB, тогда как полные модели занимают несколько гигабайт.
Развертывание LoRAX в Kubernetes
LoRAX поставляется с Helm charts и Docker-образами, поэтому развертывание в Kubernetes довольно прямолинейно.
Предварительные требования
Вам понадобятся:
- Кластер Kubernetes с NVIDIA GPU (поколение Ampere или новее: A10, A100, H100)
- Настроенный NVIDIA Container Runtime на GPU-узлах
- Локально установленные
kubectlиhelm - Постоянное хранилище для кэшей адаптеров; смонтируйте PersistentVolume в
/dataвнутри pod
Быстрый старт с официальным Helm chart
Helm — это пакетный менеджер для Kubernetes. Он упаковывает все Kubernetes-ресурсы, нужные приложению (Deployments, Services, ConfigMaps и т. д.), в единый "chart", чтобы вы могли развернуть все одной командой вместо ручного управления десятками YAML-файлов.
Predibase отключила свой публичный Helm-репозиторий в конце 2024 года, поэтому поддерживаемый workflow — клонировать репозиторий LoRAX и устанавливать chart с диска. Выполните эти команды со своей рабочей станции:
# Clone the LoRAX repository and switch into it
git clone https://github.com/predibase/lorax.git
cd lorax
# Make sure kubectl can talk to your cluster
kubectl config current-context
kubectl get nodes
# Build chart dependencies (generates charts/lorax/charts/*.tgz)
helm dependency update charts/lorax
# Optional: render manifests locally to verify everything is templating
helm template mistral-7b-release charts/lorax > /tmp/lorax-rendered.yaml
# Deploy with default settings (Mistral-7B-Instruct)
helm upgrade --install mistral-7b-release charts/lorax
# Watch the pod come up
kubectl get pods -w
# Check logs to see model loading progress
kubectl logs -f deploy/mistral-7b-release-lorax
Chart создает Deployment (по умолчанию одна реплика) и Service типа ClusterIP, слушающий порт 80. При первом запуске базовая модель скачивается из Hugging Face и загружается в память GPU, что может занять несколько минут в зависимости от сети и GPU. При последующих перезапусках используются закэшированные веса из persistent volume.
Совет: Если
helm upgrade --installвозвращаетKubernetes cluster unreachable, контекст вашего kubeconfig указывает на недоступный кластер. Запустите локальный кластер (Docker Desktop, kind, minikube) или переключитесь на доступный контекст черезkubectl config use-context. Запускkubectl get nodesперед deployment подтверждает, что API server доступен.
Настройка базовой модели и масштабирования
Вы можете подставить другую базовую модель или скорректировать ресурсы, создав собственный values file. Вот пример llama2-values.yaml:
# Use LLaMA 2 7B Chat instead of Mistral
modelId: meta-llama/Llama-2-7b-chat-hf
# Enable 4-bit quantization to save VRAM
modelArgs:
quantization: "bitsandbytes"
# Scale to 2 replicas for high availability
replicaCount: 2
# Request exactly 1 GPU per pod
resources:
limits:
nvidia.com/gpu: 1
Разверните с вашей пользовательской конфигурацией:
helm upgrade --install -f llama2-values.yaml llama2-chat-release charts/lorax
Запускайте эти команды из клонированного репозитория lorax/, чтобы Helm смог найти каталог chart.
LoRAX поддерживает популярные open-source модели из коробки: LLaMA 2, CodeLlama, Mistral, Mixtral, Qwen и другие. Актуальные дополнения смотрите в списке совместимых моделей.
Публикация сервиса
По умолчанию Service имеет тип ClusterIP, который разрешает доступ только изнутри кластера. Для внешнего трафика используйте один из вариантов:
- Создайте Service типа LoadBalancer (у cloud-провайдеров)
- Настройте Ingress с TLS termination
- Поставьте перед сервисом API gateway для аутентификации и rate limiting
Очистка
Когда закончите тестирование, освободите ресурсы GPU:
helm uninstall mistral-7b-release
Это удалит Deployment, Service и все pod'ы. Закэшированные веса моделей останутся в PersistentVolume, если не удалить его отдельно.
Работа с API LoRAX
После развертывания LoRAX предоставляет три способа взаимодействия: REST API, совместимый с Hugging Face TGI, Python client library и OpenAI-совместимый endpoint. Все три поддерживают динамическое переключение адаптеров.
REST API
Endpoint /generate принимает JSON payload'ы с вашим prompt и необязательными параметрами. Использование базовой модели без адаптера:
# Basic request to the base model (no adapter)
curl -X POST http://localhost:8080/generate \
-H "Content-Type: application/json" \
-d '{
"inputs": "Write a short poem about the sea.",
"parameters": {
"max_new_tokens": 64,
"temperature": 0.7
}
}'
Ответ включает сгенерированный текст и метаданные, такие как количество токенов и тайминги.
Загрузка конкретного адаптера
Добавьте параметр adapter_id, чтобы выбрать дообученную модель. Ниже пример с адаптером, специализированным на математике:
curl -X POST http://localhost:8080/generate \
-H "Content-Type: application/json" \
-d '{
"inputs": "Natalia sold 48 clips in April, and then half as many in May. How many clips did she sell in total?",
"parameters": {
"max_new_tokens": 64,
"adapter_id": "vineetsharma/qlora-adapter-Mistral-7B-Instruct-v0.1-gsm8k"
}
}'
При первом вызове с новым adapter_id LoRAX скачивает адаптер из Hugging Face Hub и кэширует его в /data. Последующие запросы используют кэшированную версию. Также можно загружать адаптеры из локальных путей, если указать "adapter_source": "local" вместе с путем к файлу.
Python client
Для программного доступа установите пакет lorax-client:
pip install lorax-client
Клиент оборачивает REST API в удобный интерфейс:
from lorax import Client
# Connect to your LoRAX instance (default port 8080)
client = Client("http://localhost:8080")
prompt = "Explain the significance of the moon landing in 1969."
# 1. Generate using the base model (no adapter loaded)
base_response = client.generate(prompt, max_new_tokens=80)
print("Base model:", base_response.generated_text)
# 2. Generate using a fine-tuned adapter
# The adapter_id can be a Hugging Face repo ID or a local path
adapter_response = client.generate(
prompt,
max_new_tokens=80,
adapter_id="alignment-handbook/zephyr-7b-dpo-lora",
)
print("With adapter:", adapter_response.generated_text)
Клиент поддерживает streaming, параметры decoding (temperature, top-p, repetition penalty) и token-level details. Расширенные сценарии см. в справке по клиенту.
OpenAI-совместимый endpoint
LoRAX реализует OpenAI Chat Completions API по пути /v1. Это позволяет подставить LoRAX в инструменты, ожидающие формат API OpenAI: LangChain, Semantic Kernel или пользовательские приложения.
Используйте поле model, чтобы указать, какой адаптер загрузить:
import openai
# Point the OpenAI client at LoRAX
openai.api_key = "EMPTY" # LoRAX doesn't require an API key by default
openai.api_base = "http://localhost:8080/v1"
# The model parameter becomes the adapter_id
# This allows seamless integration with tools like LangChain
response = openai.ChatCompletion.create(
model="alignment-handbook/zephyr-7b-dpo-lora",
messages=[
{"role": "system", "content": "You are a friendly chatbot who speaks like a pirate."},
{"role": "user", "content": "How many parrots can a person own?"},
],
max_tokens=100,
)
print(response["choices"][0]["message"]["content"])
Из этого следуют два практических сценария использования:
- Прямая замена. Перенесите существующие приложения с hosted-моделей OpenAI на свою инфраструктуру, изменив одну строку конфигурации.
- Интеграция с инструментами. Используйте LoRAX с любым фреймворком, который уже поддерживает API OpenAI, без собственного кода для работы с адаптерами.
Первый запрос к новому адаптеру имеет более высокую latency, пока LoRAX скачивает и загружает его. Учитывайте это в пользовательских приложениях: можно заранее прогревать популярные адаптеры или показывать состояние загрузки.
Компромиссы
В чем LoRAX хорош
- Много моделей на одном GPU. Сотни или тысячи дообученных моделей на одном GPU вместо одного deployment'а на модель. Стоимость остается почти постоянной при добавлении адаптеров.
- Нет простаивающей памяти. Адаптеры загружаются по запросу. Неиспользуемые модели ничего не стоят по VRAM. Можно держать каталог из 1,000+ специализированных моделей и платить только за те немногие, что реально обслуживают трафик.
- Throughput сохраняется. Continuous multi-adapter batching удерживает latency и throughput близкими к режиму одной модели. Бенчмарки Predibase показывают, что параллельное обслуживание 32 адаптеров добавляет минимум накладных расходов по сравнению с одним.
- TGI под капотом. Построен на Hugging Face TGI, поэтому вы получаете FlashAttention 2, paged attention, streaming и SGMV kernels для multi-adapter inference.
- Операционно зрелый стек. Docker-образы, Helm charts, Prometheus metrics, OpenTelemetry tracing. Лицензия Apache 2.0, без коммерческих ограничений.
- Широкая поддержка моделей. Работает с LLaMA 2, CodeLlama, Mistral, Mixtral, Qwen и другими. Поддерживает quantization (4-bit через bitsandbytes, GPTQ, AWQ) для снижения потребления памяти.
Ограничения
- Только LoRA. Все адаптеры должны быть получены через LoRA-style fine-tuning одной и той же базовой модели. Полные fine-tune, создающие автономные модели, не заработают без конвертации. Для разных базовых архитектур нужны отдельные deployment'ы LoRAX.
- Cold start. Первый запрос после запуска загружает базовую модель в память GPU (30–90 секунд для крупных моделей). Первый запрос к новому адаптеру добавляет latency на скачивание из Hugging Face. Учитывайте это через health checks и preload.
- Thrashing кэша при bursty load. Если трафик внезапно приходит на десятки разных адаптеров, LoRAX вынужден перемещать веса между GPU, RAM CPU и диском. Переключение адаптера из RAM занимает около 10ms, но очень большой working set может вызывать временные замедления. Следите за памятью GPU и hit rate кэша адаптеров.
- Быстро меняющийся проект. LoRAX ответвился от TGI в конце 2023 года и быстро меняется. Ожидайте частых обновлений и иногда несовместимых изменений по мере синхронизации с upstream TGI. Фиксируйте версии в production.
LoRAX vs. vLLM
vLLM — еще один high-throughput serving engine, который сравнительно недавно добавил поддержку multi-LoRA. Эти системы решают разные задачи.
| Feature | LoRAX | vLLM |
|---|---|---|
| Primary focus | Massive scale: hundreds or thousands of adapters | High throughput: maximum tokens/sec for fewer active adapters |
| Architecture | Dynamic swapping; aggressively offloads to CPU/disk | Batching tuned for concurrent execution of active adapters |
| Best for | Long-tail SaaS: 1000s of tenants, sporadic usage | High-traffic tiers: 5–10 heavily used adapters |
| Base | Hugging Face TGI | Custom PagedAttention engine |
Выбирайте LoRAX, если у вас длинный хвост адаптеров (по одному на пользователя, и большинство большую часть времени простаивает), где многоуровневый кэш дает выигрыш. Выбирайте vLLM, если у вас небольшой набор очень активных адаптеров и на первом месте максимальный raw throughput.
С чего начать
Практический путь от прототипа к production:
1. Начните с малого
Разверните LoRAX с той базовой моделью, которую уже используете, и 3–5 репрезентативными адаптерами. Убедитесь, что загрузка адаптеров работает, и измерьте базовую latency на вашей нагрузке.
2. Измеряйте и профилируйте
- Отслеживайте hit rate кэша адаптеров и память GPU под реалистичным трафиком.
- Определите горячие адаптеры (верхние 20% по объему запросов) и подумайте о preload при старте.
- Измеряйте P50, P95 и P99 latency как для кэшированных, так и для холодных загрузок адаптеров.
3. Оптимизируйте под свою нагрузку
- Если несколько адаптеров очень популярны, увеличьте выделение памяти GPU, чтобы держать больше из них горячими.
- Если нагрузка имеет длинный хвост по сотням адаптеров, настройте многоуровневый кэш, балансируя RAM и диск.
- Используйте quantization (4-bit bitsandbytes или GPTQ), если VRAM ограничена.
4. Масштабируйтесь горизонтально
Когда поведение одиночного инстанса понятно, добавляйте реплики для высокой доступности. Поставьте перед ними load balancer, который маршрутизирует по adapter_id, чтобы запросы к одному и тому же адаптеру попадали на одну и ту же реплику. Это улучшает cache locality.
5. Наблюдаемость
Настройте дашборды для утилизации GPU, метрик кэша адаптеров и latency запросов с разбивкой по адаптерам. Следите за thrashing кэша во время всплесков трафика и подстраивайте масштабирование соответственно.
С LoRAX запуск N fine-tune-моделей превращается в задачу маршрутизации на одном GPU, а не в задачу выделения ресурсов на N GPU.