Automatische Übersetzung
Dieser Artikel wurde automatisch aus der englischen Originalversion übersetzt.
LoRAX-Serving-Guide: Tausende von LoRA-Adaptern auf Kubernetes
Das Serving von Dutzenden feinabgestimmten Large Language Models bedeutete früher meist eine GPU pro Modell. LoRAX (LoRA eXchange) hält ein einzelnes Basismodell im Speicher und tauscht pro Request leichtgewichtige LoRA-Adapter per Hot-Swap aus. Die Kosten pro Token bleiben ungefähr konstant, auch wenn Sie mehr Fine-Tunes hinzufügen.
Dieser Leitfaden behandelt, was LoRA ist, wann Sie LoRAX statt vLLM wählen sollten, wie Sie es mit dem offiziellen Helm-Chart auf Kubernetes deployen und wie Sie die REST-, Python- und OpenAI-kompatiblen APIs aufrufen.
Hintergrund: Was ist LoRA?
Low-Rank Adaptation (LoRA) friert die Gewichte des vortrainierten Modells ein und injiziert kleine Matrizen mit Rangzerlegung in jede Transformer-Schicht. Statt das gesamte Modell neu zu trainieren, trainieren Sie eine kleine Menge von „Diffs“, die das neue Verhalten erfassen.
Ein vollständiger Fine-Tune eines 7B-Modells ist eine Datei mit mehr als 20GB. Ein LoRA-Adapter für dasselbe Modell liegt bei etwa 100MB. Genau dieser Unterschied macht dynamisches Serving möglich: Sie können Tausende Adapter auf Datenträger vorhalten und einen davon in Millisekunden in den GPU-Speicher laden.
Das Problem, das LoRAX löst
Multi-Model-Serving auf traditionelle Weise ist teuer. Jedes feinabgestimmte Modell benötigt seinen eigenen GPU-Speicher, daher bedeuten 50 kundenspezifische Modelle 50 Deployments oder zumindest den 50-fachen Speicherbedarf. Die Kosten skalieren mit jeder neuen Variante linear.
LoRAX ist ein Apache-2.0-Projekt von Predibase. Es erweitert den Hugging Face Text Generation Inference server um dynamisches Laden von Adaptern, tiered Weight Caching und Multi-Adapter-Batching. Zusammen ermöglicht das, Hunderte mandantenspezifische LoRA-Adapter auf einer einzelnen GPU der Ampere-Klasse zu serven, ohne Durchsatz oder Latenz zu verlieren.
Der Trick: LoRA-Fine-Tuning erzeugt kleine Delta-Gewichte statt vollständiger Modellkopien. LoRAX hält nur das Basismodell dauerhaft auf der GPU und injiziert Adapter-Gewichte bei Bedarf. Adapter, die gerade nicht verwendet werden, kosten keinen VRAM.
So funktioniert es
Dynamisches Laden von Adaptern
Adapter-Gewichte werden für jeden Request just-in-time injiziert. Das Basismodell bleibt im GPU-Speicher resident, während Adapter on the fly geladen werden, ohne andere Requests zu blockieren. Sie können Tausende Adapter katalogisieren, zahlen aber nur Speicherkosten für die Adapter, die aktiv Traffic bedienen.
Tiered Weight Caching
LoRAX staffelt Adapter über drei Ebenen: GPU-VRAM für heiße Adapter, CPU-RAM für warme Adapter und Datenträger für kalten Speicher. Diese Hierarchie verhindert Out-of-Memory-Abstürze und hält Swap-Zeiten schnell genug, dass Nutzer davon nichts merken.
Kontinuierliches Multi-Adapter-Batching
Hier verändert LoRAX das Batching-Verhalten. Es erweitert Continuous Batching so, dass es parallel über unterschiedliche Adapter hinweg funktioniert, sodass Requests an verschiedene Fine-Tunes denselben Forward Pass teilen können. Benchmarks von Predibase zeigen, dass die Verarbeitung von 1M Tokens, verteilt über 32 verschiedene Adapter, ungefähr genauso lange dauert wie 1M Tokens auf einem einzelnen Modell.
TGI darunter
LoRAX baut auf Hugging Face's Text Generation Inference (TGI) auf, daher übernehmen Sie die Optimierungen von TGI: FlashAttention 2, paged attention, SGMV-Kernels für Multi-Adapter-Inferenz und Streaming-Responses. Es ist TGI plus dynamisches Adapter-Switching.
Die Kosten pro Token bleiben ungefähr konstant
Das Diagramm macht den Punkt deutlich. Dedizierte Deployments (dunkelgrau) skalieren linear: doppelte Modellanzahl, doppelte Kosten. LoRAX (orange) hält die Kosten pro Token beim Hinzufügen von Adaptern nahezu konstant. Selbst gehostete API-Fine-Tunes von Anbietern wie OpenAI (hellgrau) können bei Multi-Model-Workloads nicht mithalten.
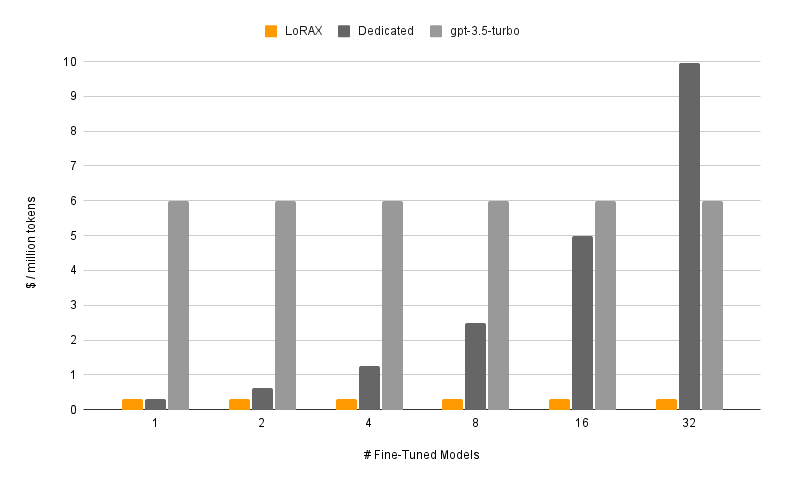
Kosten pro Million Tokens, wenn Sie mehr feinabgestimmte Modelle serven. LoRAX bleibt dank Multi-Adapter-Batching nahezu konstant; dedizierte Deployments skalieren linear. Quelle: LoRAX GitHub.
Request-Flow

Wann LoRAX sinnvoll ist
LoRAX ist in einigen konkreten Situationen sinnvoll.
- Mandantenfähige SaaS. Sie bauen eine Plattform, auf der jeder von 500 Kunden einen auf seine Daten feinabgestimmten Chatbot erhält. Der traditionelle Ansatz verlangt 500 Model-Deployments. LoRAX bedient alle 500 von einer GPU aus, indem beim Eintreffen eines Kunden-Requests der relevante Adapter geladen wird.
- Domänenspezifisches Expert Routing. Sie betreiben spezialisierte LLMs für Recht, Medizin, Finanzen und Engineering. Statt vier separater 13B-Deployments betreibt LoRAX ein LLaMA 2 13B-Basismodell und routet abhängig von der Request-Domäne zum passenden Adapter.
- Schnelles Experimentieren. Sie testen 10 Fine-Tuning-Ansätze in Produktion? Deployen Sie LoRAX einmal und wechseln Sie zwischen Varianten, indem Sie den Parameter
adapter_idändern. Keine Infrastrukturänderungen, keine Service-Neustarts. - Ressourcenbeschränkte oder Edge-Deployments. Eine einzelne NVIDIA A10G kann ein quantisiertes 7B-Basismodell plus Dutzende aufgabenspezifische Adapter hosten, statt eine GPU pro Modell zu benötigen.
Architektur: Speicherhierarchie und Request-Scheduling
LoRAX basiert auf einer dreistufigen Speicherhierarchie. Wenn Sie sie verstehen, können Sie Performance besser vorhersagen und Kapazitäten planen.

LoRAX behandelt jeden Adapter als leichtgewichtige „Ansicht“ auf das gemeinsame Basismodell. Der Scheduler bündelt Requests so, dass das Serving von 32 verschiedenen Adaptern genauso schnell sein kann wie das Serving eines einzelnen Adapters, selbst bei einem Durchsatz von einer Million Tokens. Adapter sind typischerweise 10–200MB groß, verglichen mit Full Models im Multi-GB-Bereich.
LoRAX auf Kubernetes deployen
LoRAX bringt Helm-Charts und Docker-Images mit, daher ist das Deployment auf Kubernetes unkompliziert.
Voraussetzungen
Sie benötigen:
- Einen Kubernetes-Cluster mit NVIDIA-GPUs (Ampere-Generation oder neuer: A10, A100, H100)
- Eine auf GPU-Nodes konfigurierte NVIDIA Container Runtime
- Lokal installierte
kubectlundhelm - Persistenten Speicher für Adapter-Caches; mounten Sie ein PersistentVolume im Pod nach
/data
Schnellstart mit dem offiziellen Helm-Chart
Helm ist der Package Manager für Kubernetes. Er bündelt alle Kubernetes-Ressourcen, die eine Anwendung benötigt (Deployments, Services, ConfigMaps usw.), in einem einzelnen „Chart“, sodass Sie alles mit einem Befehl deployen können, statt Dutzende YAML-Dateien manuell zu verwalten.
Predibase hat sein öffentliches Helm-Repository Ende 2024 eingestellt, daher besteht der unterstützte Workflow darin, das LoRAX-Repository zu klonen und das Chart von Datenträger zu installieren. Führen Sie diese Befehle auf Ihrer Workstation aus:
# Clone the LoRAX repository and switch into it
git clone https://github.com/predibase/lorax.git
cd lorax
# Make sure kubectl can talk to your cluster
kubectl config current-context
kubectl get nodes
# Build chart dependencies (generates charts/lorax/charts/*.tgz)
helm dependency update charts/lorax
# Optional: render manifests locally to verify everything is templating
helm template mistral-7b-release charts/lorax > /tmp/lorax-rendered.yaml
# Deploy with default settings (Mistral-7B-Instruct)
helm upgrade --install mistral-7b-release charts/lorax
# Watch the pod come up
kubectl get pods -w
# Check logs to see model loading progress
kubectl logs -f deploy/mistral-7b-release-lorax
Das Chart erstellt ein Deployment (standardmäßig ein Replica) und einen ClusterIP-Service, der auf Port 80 lauscht. Beim ersten Start wird das Basismodell von Hugging Face heruntergeladen und in den GPU-Speicher geladen, was je nach Netzwerk und GPU einige Minuten dauern kann. Bei späteren Neustarts werden die gecachten Gewichte aus dem Persistent Volume wiederverwendet.
Tipp: Wenn
helm upgrade --installKubernetes cluster unreachablezurückgibt, zeigt Ihr kubeconfig-Kontext auf einen Cluster, der offline ist. Starten Sie Ihren lokalen Cluster (Docker Desktop, kind, minikube) oder wechseln Sie mitkubectl config use-contextzu einem erreichbaren Kontext. Mitkubectl get nodesvor dem Deployment prüfen Sie, ob der API-Server erreichbar ist.
Basismodell und Skalierung anpassen
Sie können ein anderes Basismodell einsetzen oder Ressourcen anpassen, indem Sie eine benutzerdefinierte Values-Datei erstellen. Hier ist ein Beispiel für llama2-values.yaml:
# Use LLaMA 2 7B Chat instead of Mistral
modelId: meta-llama/Llama-2-7b-chat-hf
# Enable 4-bit quantization to save VRAM
modelArgs:
quantization: "bitsandbytes"
# Scale to 2 replicas for high availability
replicaCount: 2
# Request exactly 1 GPU per pod
resources:
limits:
nvidia.com/gpu: 1
Deployen Sie mit Ihrer benutzerdefinierten Konfiguration:
helm upgrade --install -f llama2-values.yaml llama2-chat-release charts/lorax
Führen Sie diese Befehle im geklonten Repository lorax/ aus, damit Helm das Chart-Verzeichnis finden kann.
LoRAX unterstützt gängige Open-Source-Modelle out of the box: LLaMA 2, CodeLlama, Mistral, Mixtral, Qwen und weitere. Prüfen Sie die Modell-Kompatibilitätsliste für die neuesten Ergänzungen.
Den Service exponieren
Der Standard-Service-Typ ist ClusterIP, was nur Zugriff aus dem Cluster heraus erlaubt. Für externen Traffic haben Sie folgende Optionen:
- Einen LoadBalancer-Service erstellen (bei Cloud-Providern)
- Ein Ingress mit TLS-Terminierung einrichten
- Ein API-Gateway für Authentifizierung und Rate Limiting davorschalten
Aufräumen
Wenn Sie mit dem Testen fertig sind, geben Sie die GPU-Ressourcen wieder frei:
helm uninstall mistral-7b-release
Dadurch werden Deployment, Service und alle Pods entfernt. Gecachte Modellgewichte bleiben im PersistentVolume erhalten, sofern Sie dieses nicht separat löschen.
Mit den LoRAX-APIs arbeiten
Nach dem Deployment bietet LoRAX drei Möglichkeiten zur Interaktion: eine zu Hugging Face TGI kompatible REST-API, eine Python-Client-Bibliothek und einen OpenAI-kompatiblen Endpoint. Alle drei unterstützen dynamisches Adapter-Switching.
REST-API
Der Endpoint /generate akzeptiert JSON-Payloads mit Ihrem Prompt und optionalen Parametern. Das Basismodell ohne Adapter verwenden Sie so:
# Basic request to the base model (no adapter)
curl -X POST http://localhost:8080/generate \
-H "Content-Type: application/json" \
-d '{
"inputs": "Write a short poem about the sea.",
"parameters": {
"max_new_tokens": 64,
"temperature": 0.7
}
}'
Die Response enthält den generierten Text und Metadaten wie Token-Anzahlen und Timing.
Einen bestimmten Adapter laden
Fügen Sie einen Parameter adapter_id hinzu, um ein feinabgestimmtes Modell gezielt anzusprechen. Hier ist ein Beispiel mit einem auf Mathematik spezialisierten Adapter:
curl -X POST http://localhost:8080/generate \
-H "Content-Type: application/json" \
-d '{
"inputs": "Natalia sold 48 clips in April, and then half as many in May. How many clips did she sell in total?",
"parameters": {
"max_new_tokens": 64,
"adapter_id": "vineetsharma/qlora-adapter-Mistral-7B-Instruct-v0.1-gsm8k"
}
}'
Beim ersten Aufruf mit einer neuen adapter_id lädt LoRAX den Adapter von Hugging Face Hub herunter und cached ihn unter /data. Nachfolgende Requests verwenden die gecachte Version. Sie können Adapter auch aus lokalen Pfaden laden, indem Sie "adapter_source": "local" zusammen mit einem Dateipfad setzen.
Python-Client
Für programmatischen Zugriff installieren Sie das Paket lorax-client:
pip install lorax-client
Der Client kapselt die REST-API mit einer sauberen Schnittstelle:
from lorax import Client
# Connect to your LoRAX instance (default port 8080)
client = Client("http://localhost:8080")
prompt = "Explain the significance of the moon landing in 1969."
# 1. Generate using the base model (no adapter loaded)
base_response = client.generate(prompt, max_new_tokens=80)
print("Base model:", base_response.generated_text)
# 2. Generate using a fine-tuned adapter
# The adapter_id can be a Hugging Face repo ID or a local path
adapter_response = client.generate(
prompt,
max_new_tokens=80,
adapter_id="alignment-handbook/zephyr-7b-dpo-lora",
)
print("With adapter:", adapter_response.generated_text)
Der Client unterstützt Streaming, Decoding-Parameter (temperature, top-p, repetition penalty) und Details auf Token-Ebene. Weiterführende Nutzung finden Sie in der Client-Referenz.
OpenAI-kompatibler Endpoint
LoRAX implementiert die OpenAI Chat Completions API unter dem Pfad /v1. Damit können Sie LoRAX in Tools einsetzen, die das API-Format von OpenAI erwarten: LangChain, Semantic Kernel oder eigene Anwendungen.
Verwenden Sie das Feld model, um festzulegen, welcher Adapter geladen werden soll:
import openai
# Point the OpenAI client at LoRAX
openai.api_key = "EMPTY" # LoRAX doesn't require an API key by default
openai.api_base = "http://localhost:8080/v1"
# The model parameter becomes the adapter_id
# This allows seamless integration with tools like LangChain
response = openai.ChatCompletion.create(
model="alignment-handbook/zephyr-7b-dpo-lora",
messages=[
{"role": "system", "content": "You are a friendly chatbot who speaks like a pirate."},
{"role": "user", "content": "How many parrots can a person own?"},
],
max_tokens=100,
)
print(response["choices"][0]["message"]["content"])
Daraus ergeben sich zwei praktische Anwendungsfälle:
- Drop-in-Replacement. Migrieren Sie bestehende Anwendungen von gehosteten Modellen von OpenAI auf Ihre eigene Infrastruktur, indem Sie eine einzige Konfigurationszeile ändern.
- Tool-Integration. Verwenden Sie LoRAX mit jedem Framework, das OpenAI's API bereits unterstützt, ohne eigenen Adapter-Code.
Der erste Request an einen neuen Adapter hat eine höhere Latenz, während LoRAX ihn herunterlädt und lädt. Berücksichtigen Sie das in nutzerseitigen Anwendungen, etwa durch Preloading populärer Adapter oder einen Ladezustand.
Trade-offs
Was LoRAX gut macht
- Viele Modelle auf einer GPU. Hunderte oder Tausende feinabgestimmte Modelle auf einer einzelnen GPU statt ein Deployment pro Modell. Die Kosten bleiben beim Hinzufügen von Adaptern nahezu konstant.
- Kein ungenutzter Speicher. Adapter werden bei Bedarf geladen. Nicht genutzte Modelle kosten keinen VRAM. Sie können einen Katalog mit mehr als 1.000 spezialisierten Modellen vorhalten und zahlen nur für die Handvoll, die aktiv Traffic bedienen.
- Der Durchsatz hält. Kontinuierliches Multi-Adapter-Batching hält Latenz und Durchsatz nahe am Single-Model-Serving. Benchmarks von Predibase zeigen, dass paralleles Serving von 32 Adaptern im Vergleich zu einem einzelnen Adapter nur wenig Overhead erzeugt.
- TGI darunter. Basiert auf Hugging Face TGI, daher übernehmen Sie FlashAttention 2, paged attention, Streaming und SGMV-Kernels für Multi-Adapter-Inferenz.
- Betrieblich vollständig. Docker-Images, Helm-Charts, Prometheus-Metriken, OpenTelemetry-Tracing. Apache 2.0, also ohne kommerzielle Einschränkungen.
- Breite Modellunterstützung. Funktioniert mit LLaMA 2, CodeLlama, Mistral, Mixtral, Qwen und weiteren. Unterstützt Quantisierung (4-bit via bitsandbytes, GPTQ, AWQ), um den Speicherbedarf zu senken.
Einschränkungen
- Nur LoRA. Alle Adapter müssen aus LoRA-artigem Fine-Tuning desselben Basismodells stammen. Vollständige Fine-Tunes, die eigenständige Modelle erzeugen, funktionieren ohne Konvertierung nicht. Unterschiedliche Basisarchitekturen benötigen separate LoRAX-Deployments.
- Cold Start. Der erste Request nach dem Start lädt das Basismodell in den GPU-Speicher (30–90 Sekunden bei größeren Modellen). Der erste Request an einen neuen Adapter hat zusätzliche Download-Latenz von Hugging Face. Planen Sie das mit Health Checks und Preloading ein.
- Cache Thrashing bei burstigem Load. Wenn Traffic plötzlich auf Dutzende unterschiedliche Adapter trifft, muss LoRAX Gewichte zwischen GPU, CPU-RAM und Datenträger verschieben. Adapter-Swaps aus dem RAM dauern etwa 10ms, aber ein sehr großes Working Set kann vorübergehende Verlangsamungen verursachen. Beobachten Sie GPU-Speicher und Cache-Hit-Raten der Adapter.
- Schnelllebiges Projekt. LoRAX wurde Ende 2023 von TGI geforkt und ändert sich schnell. Rechnen Sie mit häufigen Updates und gelegentlichen Breaking Changes, während es Upstream-TGI verfolgt. Pinnen Sie Versionen in Produktion.
LoRAX vs. vLLM
vLLM ist eine weitere High-Throughput-Serving-Engine und hat Multi-LoRA-Support erst später ergänzt. Die beiden lösen unterschiedliche Probleme.
| Feature | LoRAX | vLLM |
|---|---|---|
| Primärer Fokus | Massive Skalierung: Hunderte oder Tausende Adapter | Hoher Durchsatz: maximale Tokens/s für weniger aktive Adapter |
| Architektur | Dynamisches Swapping; aggressives Offloading auf CPU/Datenträger | Auf gleichzeitige Ausführung aktiver Adapter abgestimmtes Batching |
| Am besten geeignet für | Long-Tail-SaaS: 1000e Mandanten, sporadische Nutzung | High-Traffic-Tiers: 5–10 stark genutzte Adapter |
| Basis | Hugging Face TGI | Custom PagedAttention engine |
Wählen Sie LoRAX, wenn Sie einen Long Tail von Adaptern haben (einen pro Nutzer, die meisten die meiste Zeit inaktiv), bei dem tiered caching Vorteile bringt. Wählen Sie vLLM, wenn Sie eine kleine Menge sehr aktiver Adapter haben und roher Durchsatz am wichtigsten ist.
Erste Schritte
Eine praktische Roadmap vom Prototyp bis zur Produktion:
1. Klein anfangen
Deployen Sie LoRAX mit dem Basismodell, das Sie bereits verwenden, und 3–5 repräsentativen Adaptern. Verifizieren Sie, dass das Laden von Adaptern funktioniert, und messen Sie die Basislatenz für Ihren Workload.
2. Messen und profilieren
- Verfolgen Sie Adapter-Cache-Hit-Raten und GPU-Speicher unter realistischem Traffic.
- Identifizieren Sie heiße Adapter (die obersten 20 % nach Request-Volumen) und ziehen Sie in Betracht, sie beim Start vorzuladen.
- Messen Sie P50-, P95- und P99-Latenz sowohl für gecachte als auch für kalte Adapter-Ladevorgänge.
3. Für Ihren Workload optimieren
- Wenn einige Adapter sehr populär sind, erhöhen Sie die GPU-Speicherzuweisung, um mehr davon heiß zu halten.
- Wenn die Nutzung über Hunderte Adapter long-tail-verteilt ist, stimmen Sie den tiered cache so ab, dass RAM und Datenträger ausbalanciert sind.
- Nutzen Sie Quantisierung (4-bit bitsandbytes oder GPTQ), wenn VRAM knapp ist.
4. Horizontal skalieren
Sobald das Verhalten einer einzelnen Instanz verstanden ist, fügen Sie Replicas für hohe Verfügbarkeit hinzu. Stellen Sie einen Load Balancer davor, der nach adapter_id routet, damit Requests für denselben Adapter dieselbe Replica treffen. Das verbessert die Cache-Lokalität.
5. Monitoring
Richten Sie Dashboards für GPU-Auslastung, Adapter-Cache-Metriken und nach Adapter aufgeschlüsselte Request-Latenz ein. Achten Sie bei Traffic-Spitzen auf Cache Thrashing und passen Sie die Skalierung entsprechend an.
Mit LoRAX wird der Betrieb von N Fine-Tunes auf einer GPU zu einem Routing-Problem statt zu einem Provisioning-Problem auf N GPUs.