Automatische vertaling
Dit artikel is automatisch vertaald vanuit de oorspronkelijke Engelse versie.
LoRAX Serving-gids: Duizenden LoRA-adapters op Kubernetes
Tientallen fijn-afgestelde large language models serveren betekende vroeger vaak één GPU per model. LoRAX (LoRA eXchange) houdt één enkel basismodel in het geheugen en wisselt lichtgewicht LoRA-adapters hot-swap per request. De kosten per token blijven ongeveer vlak naarmate je meer fine-tunes toevoegt.
Deze gids behandelt wat LoRA is, wanneer je LoRAX boven vLLM kiest, hoe je het op Kubernetes uitrolt met de officiële Helm-chart, en hoe je de REST-, Python- en OpenAI-compatibele API's aanroept.
Achtergrond: wat is LoRA?
Low-Rank Adaptation (LoRA) bevriest de gewichten van het vooraf getrainde model en injecteert kleine rank-decompositiematrices in elke Transformer-laag. In plaats van het hele model opnieuw te trainen, train je een kleine set "diffs" die het nieuwe gedrag vastleggen.
Een volledige fine-tune van een 7B-model is een bestand van 20GB+. Een LoRA-adapter voor hetzelfde model is ongeveer 100MB. Dat verschil maakt dynamisch serveren mogelijk: je kunt duizenden adapters op disk bewaren en er één in milliseconden in het GPU-geheugen laden.
Het probleem dat LoRAX oplost
Multi-model serving op de traditionele manier is duur. Elk fijn-afgesteld model heeft zijn eigen GPU-geheugen nodig, dus het serveren van 50 klantspecifieke modellen vereist 50 deployments, of in elk geval 50× het geheugen. De kosten schalen lineair met elke nieuwe variant.
LoRAX is een Apache 2.0-project van Predibase. Het breidt de Hugging Face Text Generation Inference-server uit met dynamisch adapters laden, gelaagde weight-caching en multi-adapter batching. Samen maken die het mogelijk om honderden tenantspecifieke LoRA-adapters op één Ampere-klasse GPU te serveren zonder throughput of latency te verliezen.
De truc: LoRA fine-tuning produceert kleine delta weights in plaats van volledige modelkopieën. LoRAX houdt alleen het basismodel resident op de GPU en injecteert adapter weights on demand. Adapters die niet worden gebruikt kosten niets in VRAM.
Hoe het werkt
Dynamisch adapters laden
Adapter weights worden just-in-time geïnjecteerd voor elk request. Het basismodel blijft resident in het GPU-geheugen terwijl adapters on the fly laden zonder andere requests te blokkeren. Je kunt duizenden adapters catalogiseren maar betaalt alleen geheugenkosten voor de adapters die actief verkeer verwerken.
Gelaagde weight-caching
LoRAX plaatst adapters in drie lagen: GPU VRAM voor hot adapters, CPU RAM voor warmere adapters en disk voor cold storage. Deze hiërarchie voorkomt out-of-memory crashes en houdt swap-tijden snel genoeg zodat gebruikers het niet merken.
Continue multi-adapter batching
Hier verandert LoRAX het batching-gedrag. Het breidt continuous batching uit zodat het parallel werkt over verschillende adapters, waardoor requests naar verschillende fine-tunes dezelfde forward pass kunnen delen. Benchmarks van Predibase tonen dat het verwerken van 1M tokens verdeeld over 32 verschillende adapters ongeveer even lang duurt als 1M tokens op één enkel model.
TGI eronder
LoRAX bouwt op Hugging Face's Text Generation Inference (TGI), dus je erft TGI's optimalisaties: FlashAttention 2, paged attention, SGMV-kernels voor multi-adapter inference en streaming responses. Het is TGI plus dynamisch adapter-switching.
De kosten per token blijven ongeveer vlak
De grafiek maakt het punt duidelijk. Dedicated deployments (donkergrijs) schalen lineair: verdubbel het aantal modellen, verdubbel de kosten. LoRAX (oranje) houdt de kosten per token bijna vlak terwijl je adapters toevoegt. Zelfs gehoste API fine-tunes van providers zoals OpenAI (lichtgrijs) kunnen daar bij multi-model workloads niet aan tippen.
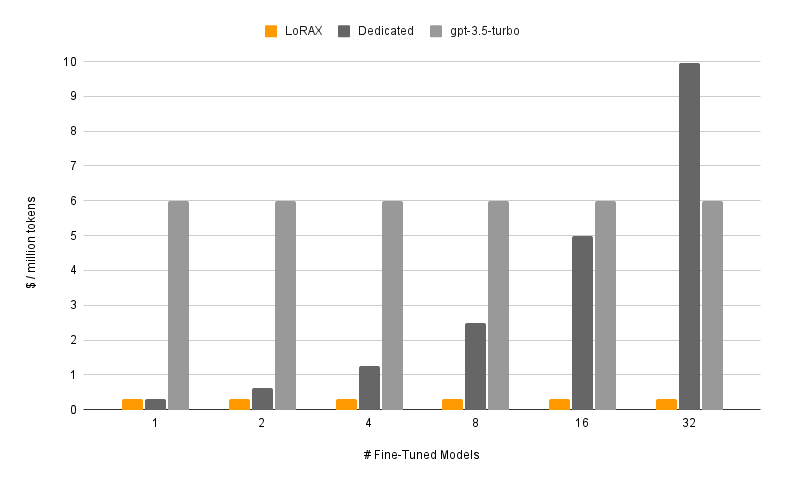
Kosten per miljoen tokens naarmate je meer fijn-afgestelde modellen serveert. LoRAX blijft bijna vlak dankzij multi-adapter batching; dedicated deployments schalen lineair. Bron: LoRAX GitHub.
Request-flow

Wanneer LoRAX gebruiken
LoRAX is zinvol in een paar specifieke situaties.
- Multi-tenant SaaS. Je bouwt een platform waar elk van 500 klanten een chatbot krijgt die fijn-afgesteld is op hun data. De traditionele aanpak vraagt om 500 model-deployments. LoRAX serveert alle 500 vanaf één GPU door de relevante adapter te laden wanneer een klantrequest binnenkomt.
- Domeinspecifieke expert-routing. Je onderhoudt gespecialiseerde LLM's voor recht, geneeskunde, finance en engineering. In plaats van vier aparte 13B-deployments draait LoRAX één basis-LLaMA 2 13B en routeert naar de juiste adapter op basis van het request-domein.
- Snelle experimentatie. Test je 10 fine-tuning-aanpakken in productie? Deploy LoRAX één keer en wissel tussen varianten door de parameter
adapter_idte wijzigen. Geen infrastructuurwijzigingen of service-restarts. - Deployments met beperkte resources of edge-deployments. Eén enkele NVIDIA A10G kan een gequantiseerd 7B-basismodel plus tientallen taakspecifieke adapters hosten, in plaats van één GPU per model.
Architectuur: geheugenhiërarchie en request-scheduling
LoRAX is gebouwd rond een geheugenhiërarchie met drie lagen. Als je die begrijpt, kun je prestaties beter voorspellen en capaciteit plannen.

LoRAX behandelt elke adapter als een lichtgewicht "view" op het gedeelde basismodel. De scheduler voegt requests samen zodat het serveren van 32 verschillende adapters net zo snel kan zijn als het serveren van één, zelfs bij een throughput van een miljoen tokens. Adapters wegen meestal 10–200MB per stuk, tegenover volledige modellen van meerdere gigabytes.
LoRAX uitrollen op Kubernetes
LoRAX wordt geleverd met Helm-charts en Docker-images, dus uitrollen op Kubernetes is eenvoudig.
Vereisten
Je hebt nodig:
- Een Kubernetes-cluster met NVIDIA GPU's (Ampere-generatie of nieuwer: A10, A100, H100)
- NVIDIA Container Runtime geconfigureerd op GPU-nodes
kubectlenhelmlokaal geïnstalleerd- Persistente opslag voor adapter-caches; mount een PersistentVolume naar
/datain de pod
Quick start met de officiële Helm-chart
Helm is de package manager voor Kubernetes. Het bundelt alle Kubernetes-resources die een applicatie nodig heeft (Deployments, Services, ConfigMaps, enz.) in één enkele "chart", zodat je alles met één commando kunt deployen in plaats van tientallen YAML-bestanden handmatig te beheren.
Predibase heeft hun publieke Helm-repository eind 2024 uitgefaseerd, dus de ondersteunde workflow is om de LoRAX-repository te clonen en de chart vanaf disk te installeren. Voer deze commando's uit vanaf je workstation:
# Clone the LoRAX repository and switch into it
git clone https://github.com/predibase/lorax.git
cd lorax
# Make sure kubectl can talk to your cluster
kubectl config current-context
kubectl get nodes
# Build chart dependencies (generates charts/lorax/charts/*.tgz)
helm dependency update charts/lorax
# Optional: render manifests locally to verify everything is templating
helm template mistral-7b-release charts/lorax > /tmp/lorax-rendered.yaml
# Deploy with default settings (Mistral-7B-Instruct)
helm upgrade --install mistral-7b-release charts/lorax
# Watch the pod come up
kubectl get pods -w
# Check logs to see model loading progress
kubectl logs -f deploy/mistral-7b-release-lorax
De chart maakt een Deployment aan (standaard één replica) en een ClusterIP Service die luistert op poort 80. Bij de eerste start wordt het basismodel gedownload van Hugging Face en in het GPU-geheugen geladen, wat afhankelijk van je netwerk en GPU een paar minuten kan duren. Latere restarts hergebruiken de gecachte weights uit het persistent volume.
Tip: Als
helm upgrade --installKubernetes cluster unreachableretourneert, wijst je kubeconfig-context naar een cluster dat offline is. Start je lokale cluster (Docker Desktop, kind, minikube) of schakel over naar een bereikbare context metkubectl config use-context. Doorkubectl get nodesuit te voeren vóór deployment bevestig je dat de API-server actief is.
Het basismodel en scaling aanpassen
Je kunt een ander basismodel gebruiken of resources aanpassen door een eigen values-bestand te maken. Hier is een voorbeeld van llama2-values.yaml:
# Use LLaMA 2 7B Chat instead of Mistral
modelId: meta-llama/Llama-2-7b-chat-hf
# Enable 4-bit quantization to save VRAM
modelArgs:
quantization: "bitsandbytes"
# Scale to 2 replicas for high availability
replicaCount: 2
# Request exactly 1 GPU per pod
resources:
limits:
nvidia.com/gpu: 1
Deploy met je aangepaste configuratie:
helm upgrade --install -f llama2-values.yaml llama2-chat-release charts/lorax
Voer deze commando's uit vanuit de gekloonde lorax/-repository zodat Helm de chart-directory kan vinden.
LoRAX ondersteunt populaire open-source modellen direct uit de doos: LLaMA 2, CodeLlama, Mistral, Mixtral, Qwen en andere. Bekijk de lijst met modelcompatibiliteit voor de nieuwste toevoegingen.
De service exposen
Het standaardtype van de Service is ClusterIP, wat alleen toegang vanuit het cluster toestaat. Voor extern verkeer kun je:
- Een LoadBalancer Service maken (bij cloudproviders)
- Een Ingress met TLS-terminatie opzetten
- Er een API-gateway voor plaatsen voor authenticatie en rate limiting
Opruimen
Als je klaar bent met testen, maak dan de GPU-resources weer vrij:
helm uninstall mistral-7b-release
Dit verwijdert de Deployment, Service en alle pods. Gecachte model weights blijven in het PersistentVolume staan tenzij je dat apart verwijdert.
Werken met de LoRAX API's
Na deployment biedt LoRAX drie manieren om ermee te werken: een REST API compatibel met Hugging Face TGI, een Python-clientlibrary en een OpenAI-compatibel endpoint. Alle drie ondersteunen dynamisch adapter-switching.
REST API
Het endpoint /generate accepteert JSON-payloads met je prompt en optionele parameters. Het basismodel gebruiken zonder adapter:
# Basic request to the base model (no adapter)
curl -X POST http://localhost:8080/generate \
-H "Content-Type: application/json" \
-d '{
"inputs": "Write a short poem about the sea.",
"parameters": {
"max_new_tokens": 64,
"temperature": 0.7
}
}'
De response bevat de gegenereerde tekst en metadata zoals token-aantallen en timing.
Een specifieke adapter laden
Voeg een parameter adapter_id toe om een fijn-afgesteld model te targeten. Hier is een voorbeeld met een in wiskunde gespecialiseerde adapter:
curl -X POST http://localhost:8080/generate \
-H "Content-Type: application/json" \
-d '{
"inputs": "Natalia sold 48 clips in April, and then half as many in May. How many clips did she sell in total?",
"parameters": {
"max_new_tokens": 64,
"adapter_id": "vineetsharma/qlora-adapter-Mistral-7B-Instruct-v0.1-gsm8k"
}
}'
Bij de eerste call met een nieuwe adapter_id downloadt LoRAX de adapter van Hugging Face Hub en cachet die onder /data. Latere requests gebruiken de gecachte versie. Je kunt adapters ook vanaf lokale paden laden door "adapter_source": "local" in te stellen samen met een bestandspad.
Python-client
Voor programmatische toegang installeer je het package lorax-client:
pip install lorax-client
De client verpakt de REST API in een nette interface:
from lorax import Client
# Connect to your LoRAX instance (default port 8080)
client = Client("http://localhost:8080")
prompt = "Explain the significance of the moon landing in 1969."
# 1. Generate using the base model (no adapter loaded)
base_response = client.generate(prompt, max_new_tokens=80)
print("Base model:", base_response.generated_text)
# 2. Generate using a fine-tuned adapter
# The adapter_id can be a Hugging Face repo ID or a local path
adapter_response = client.generate(
prompt,
max_new_tokens=80,
adapter_id="alignment-handbook/zephyr-7b-dpo-lora",
)
print("With adapter:", adapter_response.generated_text)
De client ondersteunt streaming, decoding-parameters (temperature, top-p, repetition penalty) en token-level details. Zie de clientreferentie voor geavanceerd gebruik.
OpenAI-compatibel endpoint
LoRAX implementeert de OpenAI Chat Completions API onder het pad /v1. Daardoor kun je LoRAX direct gebruiken in tools die OpenAI's API-formaat verwachten: LangChain, Semantic Kernel of custom applicaties.
Gebruik het veld model om op te geven welke adapter geladen moet worden:
import openai
# Point the OpenAI client at LoRAX
openai.api_key = "EMPTY" # LoRAX doesn't require an API key by default
openai.api_base = "http://localhost:8080/v1"
# The model parameter becomes the adapter_id
# This allows seamless integration with tools like LangChain
response = openai.ChatCompletion.create(
model="alignment-handbook/zephyr-7b-dpo-lora",
messages=[
{"role": "system", "content": "You are a friendly chatbot who speaks like a pirate."},
{"role": "user", "content": "How many parrots can a person own?"},
],
max_tokens=100,
)
print(response["choices"][0]["message"]["content"])
Hieruit volgen twee praktische use-cases:
- Drop-in replacement. Migreer bestaande applicaties van OpenAI's gehoste modellen naar je eigen infrastructuur door één configuratieregel te wijzigen.
- Tool-integratie. Gebruik LoRAX met elk framework dat OpenAI's API al ondersteunt, zonder custom adapter-code.
Het eerste request naar een nieuwe adapter heeft hogere latency terwijl LoRAX die downloadt en laadt. Houd daar in user-facing applicaties rekening mee door populaire adapters vooraf te laden of een loading state te tonen.
Trade-offs
Wat LoRAX goed doet
- Veel modellen op één GPU. Honderden of duizenden fijn-afgestelde modellen op één enkele GPU in plaats van één deployment per model. De kosten blijven vrijwel constant naarmate je adapters toevoegt.
- Geen idle-geheugen. Adapters laden on demand. Ongebruikte modellen kosten niets in VRAM. Je kunt een catalogus van 1.000+ gespecialiseerde modellen aanhouden en alleen betalen voor de paar modellen die actief verkeer verwerken.
- Throughput blijft overeind. Continuous multi-adapter batching houdt latency en throughput dicht bij single-model serving. Benchmarks van Predibase tonen dat 32 adapters parallel serveren weinig overhead toevoegt ten opzichte van één adapter.
- TGI eronder. Gebouwd op Hugging Face TGI, dus je erft FlashAttention 2, paged attention, streaming en SGMV-kernels voor multi-adapter inference.
- Operationeel compleet. Docker-images, Helm-charts, Prometheus-metrics, OpenTelemetry-tracing. Apache 2.0, dus geen commerciële beperkingen.
- Brede modelondersteuning. Werkt met LLaMA 2, CodeLlama, Mistral, Mixtral, Qwen en andere. Ondersteunt quantization (4-bit via bitsandbytes, GPTQ, AWQ) om de geheugenvoetafdruk te verkleinen.
Beperkingen
- Alleen LoRA. Alle adapters moeten afkomstig zijn van LoRA-achtige fine-tuning van hetzelfde basismodel. Volledige fine-tunes die zelfstandige modellen opleveren werken niet zonder conversie. Verschillende basisarchitecturen vereisen aparte LoRAX-deployments.
- Cold start. Het eerste request na startup laadt het basismodel in het GPU-geheugen (30–90 seconden voor grotere modellen). Het eerste request naar een nieuwe adapter heeft download-latency vanaf Hugging Face. Houd hier rekening mee met health checks en preloading.
- Cache-thrashing bij bursty load. Als verkeer plotseling tientallen verschillende adapters raakt, moet LoRAX weights verplaatsen tussen GPU, CPU RAM en disk. Adapter-swaps vanuit RAM duren ongeveer 10ms, maar een zeer grote working set kan tijdelijke vertragingen veroorzaken. Houd GPU-geheugen en cache-hit-rates van adapters in de gaten.
- Snel evoluerend project. LoRAX is eind 2023 van TGI afgesplitst en verandert snel. Verwacht frequente updates en incidentele breaking changes terwijl het upstream TGI volgt. Pin versies in productie.
LoRAX vs. vLLM
vLLM is een andere high-throughput serving-engine, en heeft recenter ook multi-LoRA-ondersteuning toegevoegd. De twee lossen verschillende problemen op.
| Feature | LoRAX | vLLM |
|---|---|---|
| Primaire focus | Massale schaal: honderden of duizenden adapters | Hoge throughput: maximaal tokens/sec voor minder actieve adapters |
| Architectuur | Dynamisch swappen; offloadt agressief naar CPU/disk | Batching afgestemd op gelijktijdige uitvoering van actieve adapters |
| Beste voor | Long-tail SaaS: 1000en tenants, sporadisch gebruik | High-traffic tiers: 5–10 intensief gebruikte adapters |
| Basis | Hugging Face TGI | Custom PagedAttention-engine |
Kies LoRAX als je een long tail van adapters hebt (één per gebruiker, de meeste meestal inactief) waarbij gelaagde caching loont. Kies vLLM als je een kleine set zeer actieve adapters hebt en ruwe throughput het belangrijkst is.
Aan de slag
Een praktische roadmap van prototype naar productie:
1. Begin klein
Deploy LoRAX met het basismodel dat je al gebruikt en 3–5 representatieve adapters. Verifieer dat adapter-loading werkt en meet de baseline-latency voor jouw workload.
2. Meten en profileren
- Houd adapter-cache-hit-rates en GPU-geheugen bij onder realistisch verkeer.
- Identificeer hot adapters (de top 20% op request-volume) en overweeg die bij startup vooraf te laden.
- Meet P50-, P95- en P99-latency voor zowel gecachte als cold adapter-loads.
3. Optimaliseer voor jouw workload
- Als een paar adapters erg populair zijn, verhoog dan de GPU-geheugentoewijzing zodat er meer hot blijven.
- Als gebruik long-tail verdeeld is over honderden adapters, tune dan de gelaagde cache om RAM en disk in balans te brengen.
- Gebruik quantization (4-bit bitsandbytes of GPTQ) als VRAM krap is.
4. Horizontaal schalen
Zodra het gedrag van één instance duidelijk is, voeg je replica's toe voor high availability. Zet er een load balancer voor die routeert op adapter_id zodat requests voor dezelfde adapter op dezelfde replica terechtkomen. Dat verbetert cache-locality.
5. Monitoren
Zet dashboards op voor GPU-utilization, adapter-cache-metrics en request-latency uitgesplitst per adapter. Let op cache-thrashing tijdens verkeerspieken en pas scaling daarop aan.
Met LoRAX wordt N fine-tunes draaien een routing-probleem op één GPU in plaats van een provisioning-probleem op N GPU's.